Condition Based Management Augmenting Software and System ReliabilityDr Samuel J Keene, Jr, FIEEE Introduction Reliability can be said to be the probability of a system performing the desired task satisfactorily for a given time period while operating under a specified environmental conditions. It was thought in the 70's that software once software was tested and worked, that it would work perfectly thereafter. A reliability of "1" was assigned to the software. The thought was once software was working; it would not change and therefore would continue operating in its operating state. By the 1990's software reliability problems were considered the "long pole in the test", or the main driver of software problems. The importance of software in the total system reliability had changed 180 degrees. The author was part of a broadcast panel on "Software Safety". One important part of that broadcast was that safety is not a characteristic parameter of software. It is a system characteristic. What I believe was meant here is that software does not operate alone: the hardware operationalizes the software. Therein the safety exposure can materialize and be brought to bear on the hardware, person in the loop, or system mission. There are many variables acting on the system and the apparent software reliability. Dr Jeffrey Voas has depicted the nesting and interaction of software and system components. See below in Figure 1: 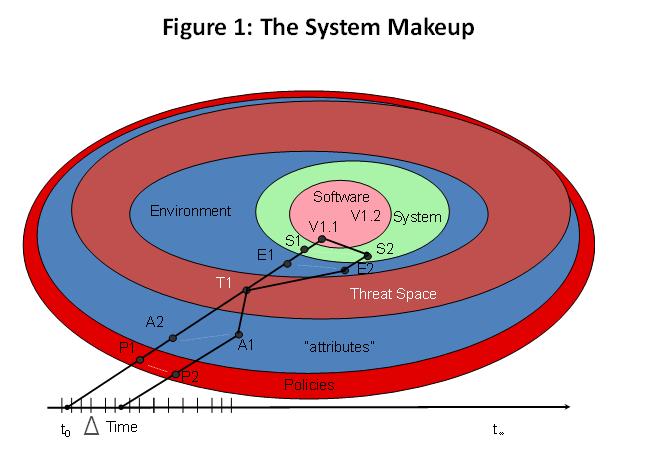 Figure 1 shows the "software" brain at the center. It is only limited by the programmer requirements mapped into it (requirements are a major challenge for reliability). The "software" is the Application Code embedded on top of the Operating System. Typically the software is evolving by going through version and point releases. These new releases fix function, safety, and reliability exposures. This "software" core then resides on hardware components. The hardware is also subject to updates over time. The "environment" contains weather related components, as the job flow, internal components status. This is all the things that the "software" must handle besides doing its main functional tasks. Note the world of systems and software is dynamic and ever changing. The particular challenge is to assure the system (and software) behave appropriately across all system and environment variations. In the end, it should be noted that it is usually the software which is changed to adapt to unwanted variations through other parts of the system or the environment. This means that software often gets the rap when all it is doing is making up for some other system component deficiency. Sometimes we hear in the newspapers of some software fault being found years after the software was released. The disparaging feeling these announcements give is" How come it has taken so long to find this bug?" A part of the answer is that it may have taken that long a period of time for that failure to be manifest. Time or aging can be a failure driver. Also the system is evolving. Typically there may changes in: the hardware, the user application, the system software and application software or even the way the user uses the system. Aging signals A colleague of mine, who was a plant manager for 3M shared an experience he had touring an automobile factory in Detroit as a young man. A smooth running assembly line was demonstrated by the factory tour guide. He showed how simple it was to determine if a line was running properly. He allowed us to put our hands on the line and feel the rhythm. That was probably the major teaching incident that kind of focused me on vibration. All machines have a certain rhythm. Today we have various devices to isolate problems. Placing your hand on machine allows you to sense the rhythm. In many cases improper rhythm indicates a bearing may be going out, drive gears may be wearing, hydraulic fluid may be pulsing, and if we wait long enough we know we're going to have a shutdown. It is an indication of an increasing problem and calls for preventative maintenance. There are similar signals today in our complex systems. System operators can key in on those signals and take preventative action. A company that I was associated with had a 24-7, safety critical computer application. Two computers were operational and one stood in "Hot Standby" mode. The operators would notice that one of the two operating computers would slow down. Seeing this they would vary that computer off line while replacing it with hot stand-by computer. This action restored the computer speed and kept the system operating satisfactorily. We used to have to take the same preventative actions with the MS Windows operating system. "Blue screens" were a common malady in the 1990's with PC's. This prompted PC users to reboot their PC before beginning typing a long paper, for instance. We would also regularly save our documents to file, in case of the PC locking up. This is a good practice now but a necessary one back then. The tri-plex computers were essentially being rebooted when they were being cycled from off line to on line. This involves occasionally stopping the running software, "cleaning" its internal state and/or its environment and then restarting it. This is labeled software rejuvenation. Notably, we are rejuvenating the system environment, not the software itself. This action reduces the likelihood of sudden aging-related failures. These system restarts can be can be applied at the discretion of the user/ administrator when system loads are least, e.g., in the middle of the night. postponing/preventing crash failures and/or performance degradation. So, software aging results in a deterioration of OS resources, depletion of free resources, and the accumulation of internal errors. The software ages as the queues build up, internal errors accumulate, memory leaks increase, memory fragments, round off errors occur, and data gets corrupted. Professor Kishor S. Trivedi, Duke University, North Carolina, USA has been a long term researcher in the area of software reliability and rejuvenation. Two of his system data graphs are shown below. 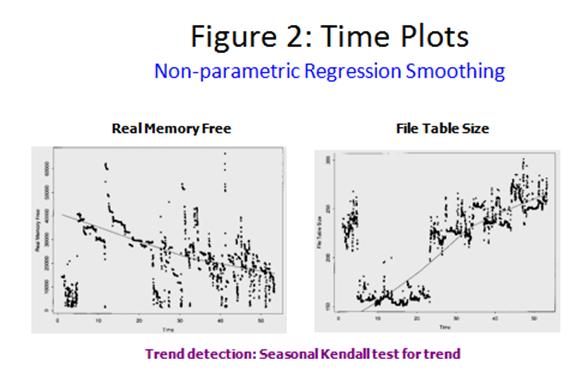 This shows that the real memory is being depleted over time, thus further constraining the space the operating code works in. This resource reduction slows the response time of the software. The slower the code gets, the more problematic the software can become. Figure 3 shows the slowing response time resulting from depletion of system resources. 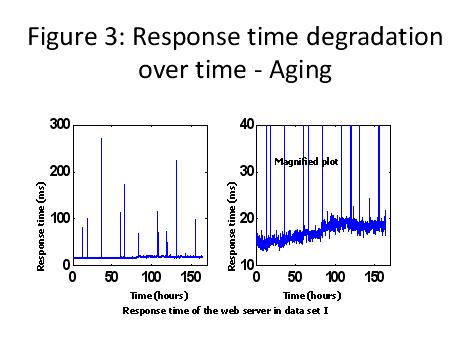 A classic example of depletion of system resources impacting reliability Conclusion: Some useful references on Software Rejuvenation for further study |
||